I’m still not able to produce a long sequence of sound…
You can see here what is the best sound I generate so far
I had no time to test in the frequency domain, I spend all my time training a lot of different models in the time domain and nothing worked out… I tried the following too see where is the problem:
- Check if the non-linearities were saturated
- Check if the way I generated the batches was fine
- Check if my implementation of RMSprop was doing the same thing as other implementations
- Check and double-check if everything is well linked in my implementations of LSTM and GRU
And everything seems fine.
I tried a lot of things:
- Used GRU and LSTM
- Varying the number of layers from 1 up to 5
- Varying the number of hidden units from 200 up to 2000
- Varying inputs length from 200 up to 32000
- Varying the sequence length from 6 up to 60
- etc…
which end up producing three different things:
- Nothing (no sound)
- Noise (like the end of what is shown here but louder)
- One note and then noise… (which is the best I got)
As presented in a previous post, the strategy was always the same; train the model to predict what’s next and then, using a seed, use the predictor as a generator.
Here is the spectrogram of the seed concatenated to what I generated. You can easily guess where the generation started…

Even though it’s really bad and unimpressive it still menages to get some frequency right before fading away. The model which does it is a three layers GRU with no end layer (the top hidden cell is directly use in the cost). Maybe the model is just not train enough as shown by the learning curve (on the valid set) here:
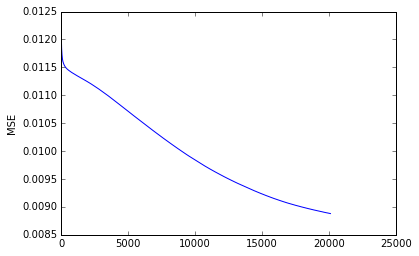
which seems to still go down, just really, really slowly. It took one whole day to train this model on a GPU.
I really don’t know where it goes wrong and if I had to restart it over I’ll definitely use a library like lasagne or blocks. It was probably not a great idea the rebuild the wheel to solve directly this task but I will for sure make it work this summer by first testing my code on a standard data set like TIMIT. I should have realize earlier that I wouldn’t have the time to make it work and start using a library but I didn’t.
Tomorrow I will try lasagne and hopefully produce something.

Did you try initializing your forget gates to 1? And are you doing gradient clipping?
My implementation is really similar to yours otherwise from what I can see, and my audio definitely fades over time and zeroes out eventually, but those are the two things I can think of that we’re maybe doing differently.
LikeLike
Yes I did try to initialize the forget gate to one (and two) but it didn’t help. But I didn’t try gradient clipping because I saw no saturation on my trained model hence I conclude that the gradient wasn’t doing some crazy stuff (maybe I’m wrong here).
For the fading problem I believe it’s because that from the model perspective if there is some incertitude about his prediction, it is better off predicting something closer to the mean. For example if 90% confident that y = 0.5 he might say 0.45 if the mean is 0. Hence the model is expected to underestimate the amplitude of what it tries to predict and this underestimation exponentially grow when we use our prediction as input.
By the way, the sound you produce is kinda cool 🙂
LikeLike